
Python Samples
Extract Folder and File Names to Multi-Sheet Excel
import os
import pandas as pd
def extract_folder_file_names(root_dir, output_excel):
"""
Extracts folder and file names from a directory and saves them to an Excel file,
splitting data into multiple sheets if the total number of rows exceeds Excel's limit.
Args:
root_dir (str): The path to the root directory.
output_excel (str): The path to the output Excel file (e.g., "output.xlsx").
"""
all_data = []
print(f"Scanning directory: {root_dir}...")
for root, dirs, files in os.walk(root_dir):
for dir_name in dirs:
all_data.append({'Type': 'Folder', 'Name': dir_name, 'Path': os.path.join(root, dir_name)})
for file_name in files:
all_data.append({'Type': 'File', 'Name': file_name, 'Path': os.path.join(root, file_name)})
print(f"Found {len(all_data)} items (folders/files).")
# Define the maximum rows per Excel sheet (1,048,576 total rows, including header)
# So, we can write 1,048,575 data rows per sheet.
MAX_ROWS_PER_SHEET = 1048575
if not all_data:
print("No folders or files found to write to Excel.")
return
# Create an Excel writer object
# The 'with' statement ensures the Excel file is properly closed
with pd.ExcelWriter(output_excel, engine='openpyxl') as writer:
# Calculate the number of sheets needed
num_sheets = (len(all_data) + MAX_ROWS_PER_SHEET - 1) // MAX_ROWS_PER_SHEET
print(f"Writing data to {num_sheets} sheet(s) in {output_excel}...")
for i in range(num_sheets):
start_row = i * MAX_ROWS_PER_SHEET
end_row = min((i + 1) * MAX_ROWS_PER_SHEET, len(all_data))
# Get the chunk of data for the current sheet
sheet_data = all_data[start_row:end_row]
# Create a DataFrame for the current sheet's data
df_sheet = pd.DataFrame(sheet_data)
# Define the sheet name
sheet_name = f"Sheet{i + 1}"
# Write the DataFrame to the current sheet
df_sheet.to_excel(writer, sheet_name=sheet_name, index=False)
print(f" - Wrote {len(sheet_data)} rows to '{sheet_name}'.")
print(f"Successfully extracted folder and file names to '{output_excel}'.")
if __name__ == "__main__":
# Example usage:
# root_directory = "C:\\Users\\Kishore\\Desktop\\New"
# output_file = "C:\\Users\\Kishore\\Desktop\\New\\output.xlsx"
root_directory = input("Enter the path to the root directory: ")
output_file = input("Enter the path to the output Excel file (e.g., C:\\path\\to\\file.xlsx): ")
# Basic validation for output file extension
if not output_file.lower().endswith(('.xlsx', '.xls')):
print("Error: Output file must have a .xlsx or .xls extension.")
else:
extract_folder_file_names(root_directory, output_file)
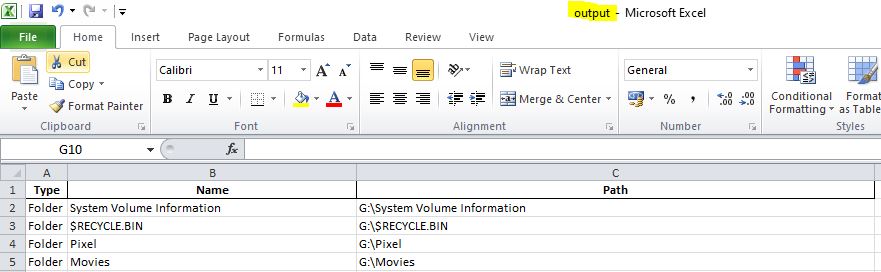
Input Commands & Output
PS D:\Python\Extract> python D:\Python\Extract\main.py
Enter the path to the root directory: G:\
Enter the path to the output Excel file (e.g., C:\path\to\file.xlsx): C:\Users\Kishore\Desktop\New\output.xlsx
Scanning directory: G:\...
Found 1301168 items (folders/files).
Writing data to 2 sheet(s) in C:\Users\Kishore\Desktop\New\output.xlsx...
- Wrote 1048575 rows to 'Sheet1'.
- Wrote 252593 rows to 'Sheet2'.
Successfully extracted folder and file names to 'C:\Users\Kishore\Desktop\New\output.xlsx'.
PS D:\Python\Extract>
Youtube Video Summary and Chapters using Bedrock LLM
# install dependencies first:
# pip install youtube-transcript-api openai pytube
import boto3
import json
from youtube_transcript_api import YouTubeTranscriptApi
from urllib.parse import urlparse, parse_qs
# Configure AWS Bedrock client
bedrock_runtime = boto3.client(
"bedrock-runtime",
region_name="us-east-1" # Use the region where Llama 3.3 70B is available
)
MODEL_ID = "anthropic.claude-v2" # Llama 3.3 70B Instruct
def extract_video_id(url):
query = urlparse(url)
if query.hostname == 'youtu.be':
return query.path[1:]
elif query.hostname in ('www.youtube.com', 'youtube.com'):
if query.path == '/watch':
return parse_qs(query.query)['v'][0]
elif query.path[:7] == '/embed/':
return query.path.split('/')[2]
elif query.path[:3] == '/v/':
return query.path.split('/')[2]
return None
def get_transcript(video_id):
transcript = YouTubeTranscriptApi.get_transcript(video_id)
#print("full_text_transcript", transcript)
full_text = ' '.join([entry['text'] for entry in transcript])
#print("full_text", full_text)
return full_text
def summarize_and_chapterize(transcript):
system_prompt = (
"You are an expert summarizer.\n\n"
"TASK:\n"
"1. Summarize the following video transcript.\n"
"2. Break the content into well-titled chapters with timestamps (assume even spacing).\n"
"3. Format output like this:\n\n"
"### Summary\n"
"<"Summary here">\n\n"
"### Chapters\n"
"- 00:00 - Introduction\n"
"- 02:13 - Topic 1: ...\n"
"- 05:47 - Topic 2: ...\n\n"
"TRANSCRIPT:\n"
)
prompt = f"{system_prompt}{transcript[:7000]}" # Claude v2 can handle more, but keep conservative
body = {
"prompt": f"\n\nHuman: {prompt}\n\nAssistant:",
"max_tokens_to_sample": 2048,
"temperature": 0.5,
"top_k": 250,
"top_p": 0.9,
"stop_sequences": ["\n\nHuman:"]
}
response = bedrock_runtime.invoke_model(
modelId=MODEL_ID,
contentType="application/json",
accept="application/json",
body=json.dumps(body)
)
result = json.loads(response['body'].read())
return result['completion']
def summarize_youtube_video(url):
video_id = extract_video_id(url)
if not video_id:
return "Invalid YouTube URL"
print(f"[+] Fetching transcript for video ID: {video_id}")
transcript = get_transcript(video_id)
print("transcript", transcript)
print("[+] Sending to LLM for summary and chapter creation...")
result = summarize_and_chapterize(transcript)
print("result", result)
return result
#return transcript
# Example usage
if __name__ == "__main__":
url = input("Enter YouTube video URL: ")
output = summarize_youtube_video(url)
print("\n--- Generated Summary and Chapters ---\n")
print(output)